La SEO è una disciplina molto complessa, che spazia dall’architettura di un sito allo sviluppo lato codice, passando per le performance dei server e la struttura di pagine e contenuti, senza dimenticare tutti quei fattori esterni al sito, denominati SEO Off Page.
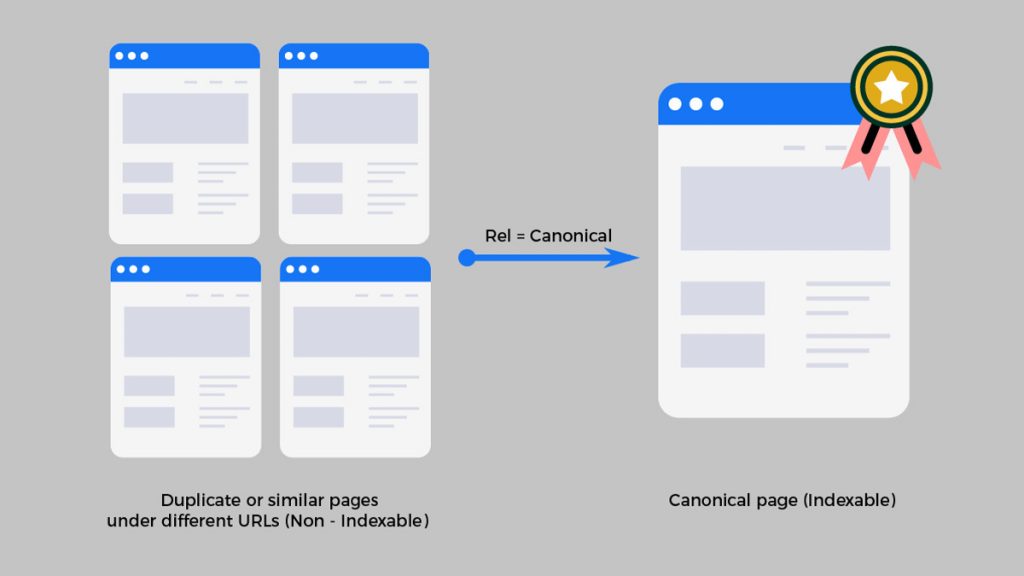
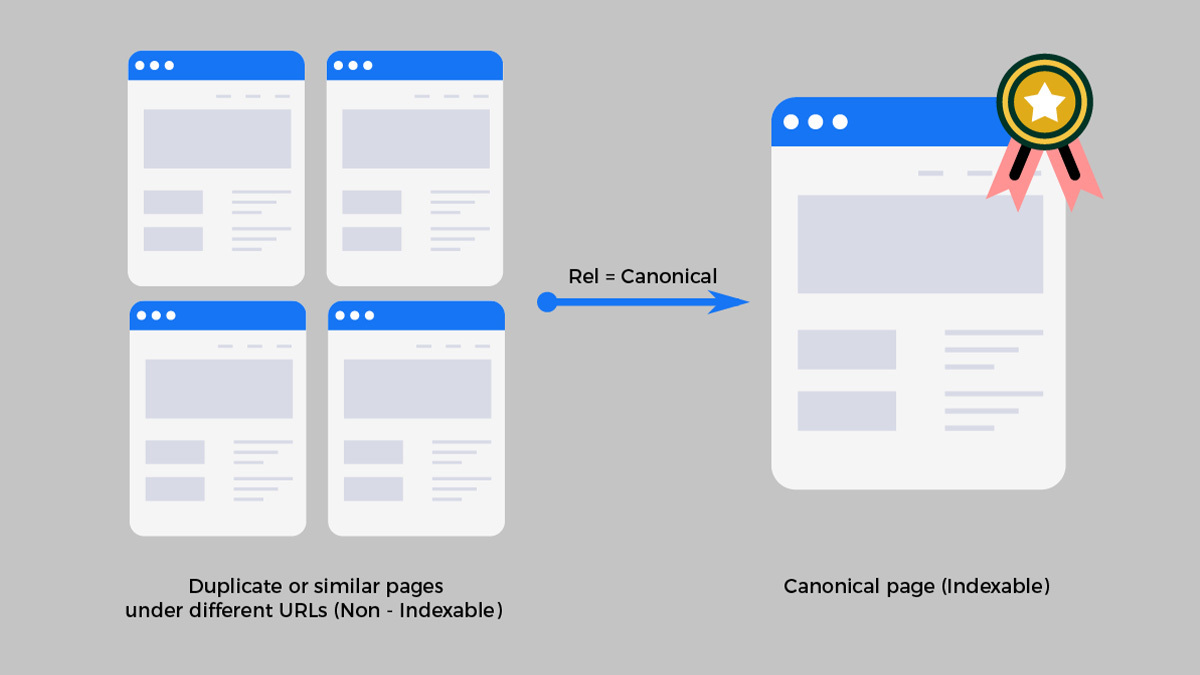
Uno degli elementi di cui tenere conto sono i canonical Tag, o Rel=canonical.
Di cosa si tratta? Partiamo dalla definizione che ci fornisce Google:
“Un URL canonico è l’URL della pagina che Google ritiene più rappresentativo tra un insieme di pagine duplicate sul tuo sito. Ad esempio, se hai più URL per la stessa pagina (example.com?dress=1234 e example.com/dresses/1234), Google ne sceglie uno come canonico.”
Non è molto chiaro, vero? In effetti, non è così facile da capire. Proviamo a rendere il tutto un po’ più semplice, spiegando cosa sono e a cosa servono i canonical Tag.
Cosa sono i Canonical Tag
Riprendendo la definizione, un po’ criptica, fornita da Google, si parla di URL Canonical quando su un sito web sono presenti più pagine duplicate, ovvero più pagine che identificano un medesimo contenuto.
Come spiega correttamente il team di MOZ in un articolo dedicato a questo argomento (lo trovi qui), pensando ai canonical ci si potrebbe chiedere:
“Ma perché mai dovrei avere più pagine identiche sul nostro sito?”.
In effetti è una domanda più che sensata, ma lo è solo per un essere umano.
Quando noi creiamo una pagina web ci preoccupiamo di renderla unica, e la sua URL identifica esattamente quel contenuto e non un altro, ma non è proprio così, almeno dal punto di vista del crawler del motore di ricerca.
Facciamo un esempio. Il nostro sito web può essere raggiunto tramite url differenti, ma che rimandano tutte alla stessa pagina:
- https://www.open-box.it;
- http://www.open-box.it;
- www.open-box.it
- open-box.it.
Per l’utente che giunge sul nostro sito non fa alcuna differenza, ma per il motore di ricerca sì, e per farlo capire a Google o simili si può utilizzare il Canonical Tag o rel=canonical.
Si tratta di un metodo attraverso il quale possiamo comunicare ai motori di ricerca che un URL specifico rappresenta la copia master di una pagina.
Noi lo abbiamo fatto, comunicando al motore di ricerca di considerare la pagina principale quella completa di https e www.
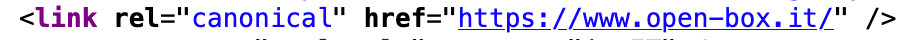
In questo modo evitiamo che il crawler del motore perda tempo prezioso (crawl budget) nello scansionare e indicizzare più copie dello stesso contenuto.
Citando MOZ:
“In pratica, il tag canonical indica ai motori di ricerca quale versione di un URL desideri venga visualizzata nei risultati di ricerca.”
Perché si creano più URL per lo stesso contenuto?
Abbiamo visto come spesso ciò che noi consideriamo un unico contenuto, raggiungibile solo attraverso una URL specifica, possa in realtà presentare delle varianti.
Ma perché questo succede? Beh, alcuni esempi li abbiamo già illustrati prima, ovvero la possibilità di raggiungere la pagina inserendo https, http, www, escludendo il www, ma non sono le uniche ragioni, che Google elenca e noi riportiamo di seguito.
- Per supportare più tipi di dispositivi:
- https://example.com/news/koala-rampage (desktop)
- https://m.example.com/news/koala-rampage (mobile)
- https://amp.example.com/news/koala-rampage (AMP)
- Per attivare gli URL dinamici per elementi come parametri di ricerca o ID di sessione:
- https://www.example.com/products?category=dresses&color=green
- https://example.com/dresses/cocktail?gclid=ABCD
- https://www.example.com/dresses/green/greendress.html
- Se il sistema del blog salva automaticamente più URL quando viene inserito uno stesso post in più sezioni:
- https://blog.example.com/dresses/green-dresses-are-awesome/
- https://blog.example.com/green-things/green-dresses-are-awesome/
- Se il server è configurato per pubblicare gli stessi contenuti per le varianti www/non www e/o http/https e porta di protocollo:
- https://example.com/green-dresses
- https://example.com/green-dresses
- https://www.example.com/green-dresses
- https://example.com:80/green-dresses
- https://example.com:443/green-dresses
- Se i contenuti proposti in un blog da distribuire in syndication su altri siti vengono copiati in parte o per intero su questi domini:
- https://news.example.com/green-dresses-for-every-day-155672.html (post distribuito in syndication)
- https://blog.example.com/dresses/green-dresses-are-awesome/3245/ (post originale).
Ancora una volta il gigante tech riesce a rendere le cose un po’ più complicate di quello che sono (almeno a parole). Quindi, proviamo a chiarire il tutto con un esempio semplice.
Spiegazione for dummies
Mettiamo il caso che tu voglia acquistare il libro del nostro Matteo Pogliani “Influencer marketing. Valorizza le relazioni e dai voce al tuo brand. Prassi, strategie e strumenti per gestire influenza e relazioni” su Amazon.
Quello che devi fare è andare sul sito, fare una ricerca, cliccare sul libro e aprire la pagina prodotto. Bene, se ci fai caso l’URL è la seguente (o simile):
- https://www.amazon.it/Influencer-marketing-Valorizza-relazioni-strategie/dp/885791058X/ref=sr_1_1?keywords=matteo+pogliani&qid=1669896105&qu=eyJxc2MiOiIxLjUwIiwicXNhIjoiMC4wMCIsInFzcCI6IjAuMDAifQ%3D%3D&sprefix=matteo+pogliani%2Caps%2C89&sr=8-1
Come puoi notare, nella URL ci sono la keyword utilizzata da te per cercare il prodotto e una serie di numeri e lettere. Se, però, decidi di acquistare il libro in formato Kindle, e clicchi sull’apposito pulsante, la URL cambia nella seguente:
- https://www.amazon.it/Influencer-Marketing-Valorizza-relazioni-EDIZIONE-ebook/dp/B0854CX985/ref=tmm_kin_swatch_0?_encoding=UTF8&qid=1669896105&sr=8-1
È differente, giusto? Bene, mettiamo ora il caso che tu voglia segnalare questo prodotto ad un tuo amico o collega. Cliccando sull’icona della condivisione e selezionando “Copia Link” ti verrà fornita questa URL:
- https://www.amazon.it/dp/885791058X?ref_=cm_sw_r_cp_ud_dp_3DDADAWK8ZWB48CAF0B1
Ancora un’altra URL, quindi, che però identifica sempre la stessa pagina prodotto.
Tante pagine diverse che indicano lo stesso contenuto. Come fa Amazon a segnalare al motore di ricerca qual è la URL genitore, quella da seguire? Inserendo il rel=“canonical” (che è ancora differente rispetto a tutte le altre!).

Lo stesso potrebbe capitare in un e-commerce che vende magliette. Ogni maglia ha la sua pagina prodotto, ma esistono delle varianti (colore, taglia, disegno, ecc…), e non ha senso creare tante pagine differenti per ognuna di esse. Si usano delle variabili alfanumeriche o di altro genere e si segnala al motore di ricerca il Canonical.
Anche l’utilizzo di un codice di tracciamento, come spesso fanno gli influencer quando propongono un prodotto o servizio o durante le campagne di advertising (?utm=), va a modificare la URL di una pagina già esistente e raggiungibile con un altro percorso.
Insomma, la presenza di situazioni del genere è fisiologica, quello che conta è fare attenzione e segnalare il Canonical inserendo il tag rel=“canonical”.
Come si segnala una pagina Canonical a Google?
Esistono differenti modi per comunicare al motore di ricerca lo standard da seguire per individuare la URL Canonical a cui prestare maggiore attenzione.
Ecco lo schemino fornito da Google sui metodi da utilizzare, con relativi pro e contro.
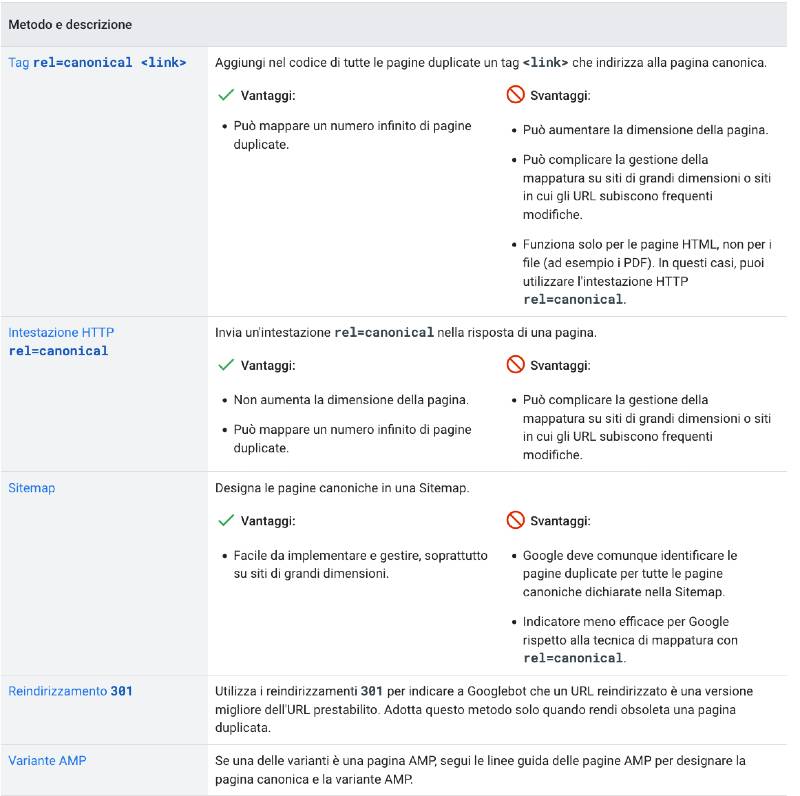
La scelta è completamente nostra, nel senso che Google non ci fornisce alcuna preferenza, ma almeno ci segnala alcune linee guida da seguire.
- Non utilizzare il file robots.txt per la canonicalizzazione;
- Non utilizzare lo strumento per le rimozioni di URL per la canonicalizzazione perché rimuove tutte le versioni di un URL dalla Ricerca;
- Non specificare URL diversi come canonici per una stessa pagina utilizzando le stesse o diverse tecniche di canonicalizzazione (ad esempio, non specificare un URL in una Sitemap e un altro URL per la stessa pagina utilizzando rel=”canonical”);
- Non utilizzare noindex per impedire la selezione di una pagina canonica. Questa istruzione ha lo scopo di escludere la pagina dall’indice, non di gestire la scelta di una pagina canonica;
- Specifica una pagina canonica quando utilizzi i tag hreflang;
- Utilizza per il link l’URL canonico, anziché un URL duplicato, quando stabilisci i collegamenti all’interno del tuo sito. Utilizzare sempre lo stesso URL per i link aiuta Google a comprendere quale sia la tua preferenza per l’URL canonico;
- Preferire HTTPS a HTTP per gli URL canonici.
Ma è obbligatorio usare il Canonical Tag?
No, non è obbligatorio, ma è fortemente raccomandato. Si tratta, in effetti, di un segnale facoltativo che il webmaster vuole fornire al crawler del motore di ricerca per ottimizzare i processi di scansione, indicizzazione e posizionamento delle pagine.
Come sappiamo, il crawler del motore di ricerca destina al nostro sito solo una piccolissima porzione di tempo; sprecarlo per fargli seguire URL duplicati è un errore da evitare.
Come segnala in un articolo Joshua Hardwick, Head of Content di Ahrefs, a Google non piacciono i contenuti duplicati, perché rende più difficile per loro scegliere:
- quale versione di una pagina indicizzare (ne indicizzerà solo una!);
- quale versione di una pagina classificare per le query pertinenti;
- se deve consolidare il “link equity” su una pagina o dividerlo tra più versioni.
L’inserimento di un Canonical Tag risolve questi problemi, rendendo più efficace il processo.
Come avviene la canonicalizzazione
Per inserire un Canonical TAG è sufficiente utilizzare una sintassi semplice, da inserire nella sezione <head> di una pagina web, così:
<link rel=“canonical” href=“https://sitoesempio.it/pagina-esempio/” />
Come consigliato da John Muller, però, è preferibile usare il link per interno, quindi comprensivo di “https://” (è meglio usare l’HTTPS se presente invece dell’HTTP).
Se non sei pratico di codice e non hai idea di come inserire un tag html nell’head della pagina, puoi usare un plugin di WordPress come Yoast.
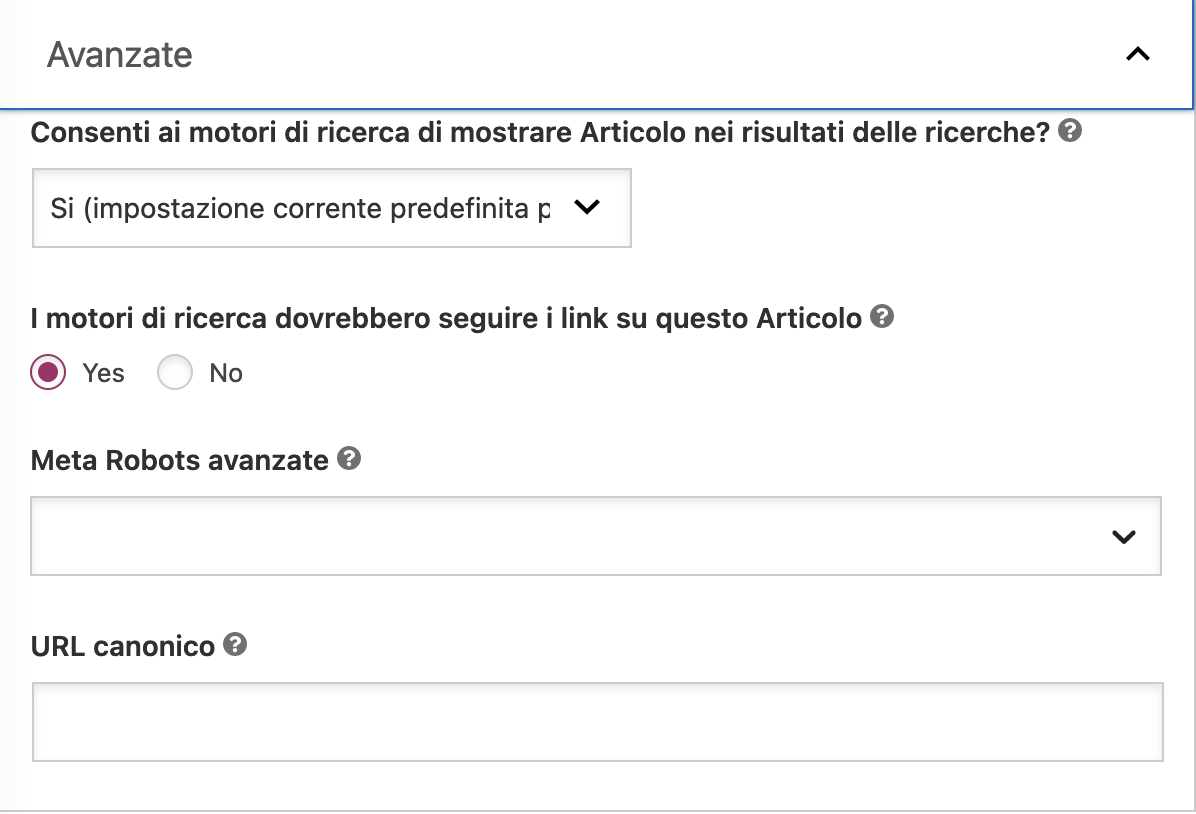
Se non lo fai, sarà Google a decidere quale versione duplicata della pagina indicizzare, in base ad una serie di fattori:
- se la pagina viene pubblicata tramite HTTP o HTTPS;
- la qualità della pagina;
- la presenza dell’URL in una Sitemap e di qualsiasi etichettatura di tipo rel=canonical.
In realtà, come racconta il solito Muller in questo video, puoi anche indicare la tua preferenza tramite queste tecniche, ma Google, per vari motivi, potrebbe comunque scegliere come canonica una pagina diversa da quella che preferiresti tu perché ritenuta la versione migliore.
Perché Google è Google, e fa come gli pare!
Francesco Ambrosino
Padre³, campione di salto con l'ansia. Dopo i pasti, esigo una cosa dolce. Scrivo roba sul uebbe.



